爬山虎采集器是一款适合绝大多数网站的网页信息采集软件,爬山虎采集器能够达到智能识别、快速采集、生成多格式数据输出的效果,满足您对指定网页数据采集的需求。
爬山虎采集器是一款适合绝大多数网站的网页信息采集软件,爬山虎采集器能够达到智能识别、快速采集、生成多格式数据输出的效果,满足您对指定网页数据采集的需求。
1、一键提取数据:简单易学,通过可视化界面,鼠标点击即可抓取数据。
2、快速高效:内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据。
3、适用于各种网站:能够采集互联网99%的网站,包括单页应用、Ajax加载等等动态类型网站。
4、导出数据类型丰富,可以将采集到的数据导出为Csv、Excel以及各种数据库,支持api导出。
1、向导模式:简单易用,轻松通过鼠标点击自动生成;
2、脚本定时运行:可按照计划定时运行,无需人工;
3、独创高速内核:自研的浏览器内核,速度飞快,远超对手;
4、智能识别:对于网页中的列表、表单结构(多选框下拉列表等)能够智能识别;
5、广告屏蔽:定制的广告屏蔽模块,兼容AdblockPlus语法,可添加自定义规则;
6、多种数据导出:支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等。
1、自动识别列表数据,通过智能算法,一键提取数据;
2、自动识别分页技术,通过算法智能识别、采集分页数据;
3、混合浏览器引擎和HTTP引擎,兼顾了易用性和效率。
一:输入采集网址
打开软件,新建任务,输入需要采集的网站地址。
二:智能分析,全程自动化提取数据
进入到第二步后,爬山虎采集器全自动智能分析网页,并且从中提取出列表数据。
三:导出数据到表格、数据库、网站等
运行任务,将采集到的数据导出为表格、网站以及各种数据库,支持api导出。
可支持windows XP以上的系统。
.Net 4.0 Framework框架,下载地址
第一步:打开下载好的安装包,直接选择运行。
第二步:接收相关条款后,运行安装程序PashanhuV2Setup.exe。 install
第三步:然后一直点击下一步,直到完成。
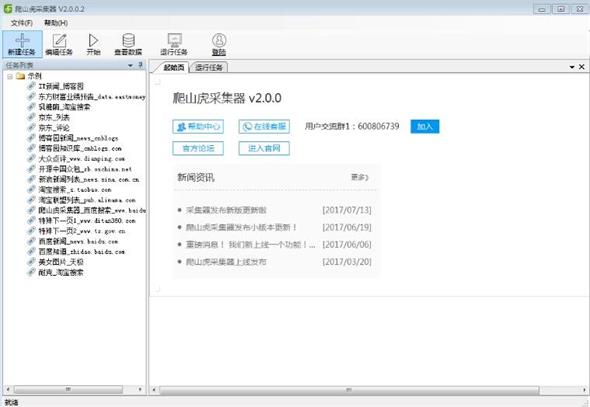
第四步:安装完成后,可以看到爬山虎采集器V2的主界面 main
1、如何采集手机版网页的数据?
一般情况下,一个网站有电脑版网页和手机版网页,如果电脑版(PC)网页的反爬虫很严格的话,我们就可以尝试抓取手机网页。
①选择新建编辑任务;
②在新建的【编辑任务】中,选择【第三步、设置】;
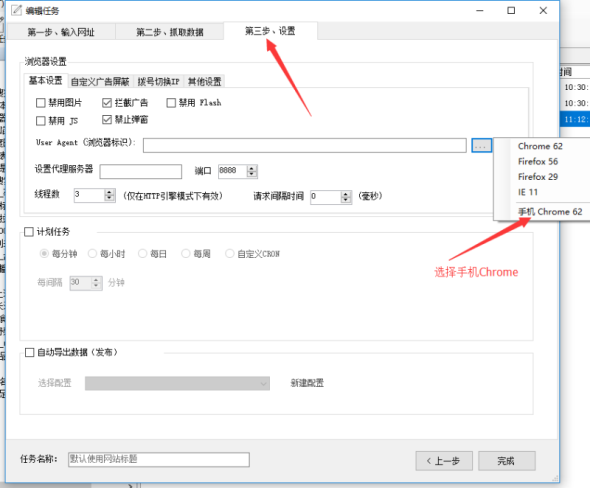
③设置UA(浏览器标识)为“手机”即可。
2、如何手动选择列表数据(当自动识别失败时)
在采集列表页时,如果自动识别列表失败,或者识别的数据不是我们想到的数据,这时我们就需要手动选择列表数据。
如何手动选择列表数据呢?
①点击【清空所有】,把已有字段清空掉。
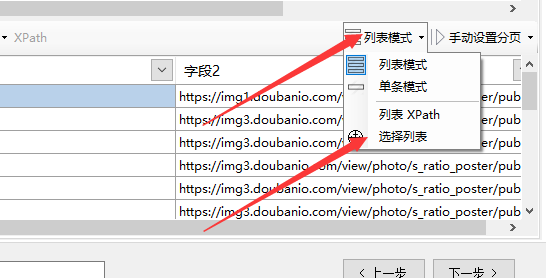
②点击菜单栏的【列表数据】,选择【选择列表】
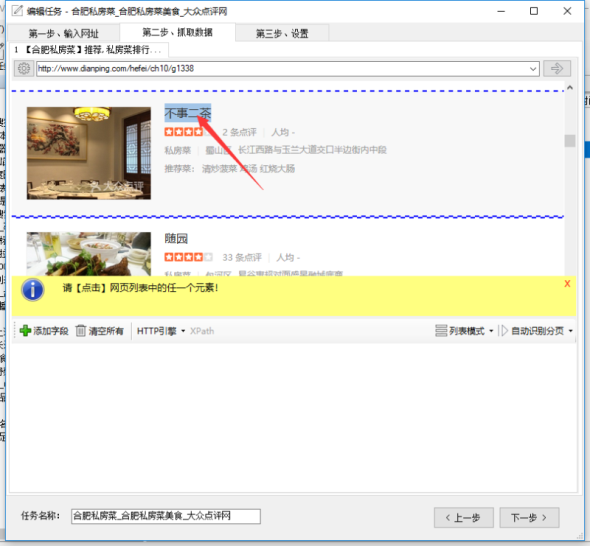
③用鼠标点击列表中的任一元素。
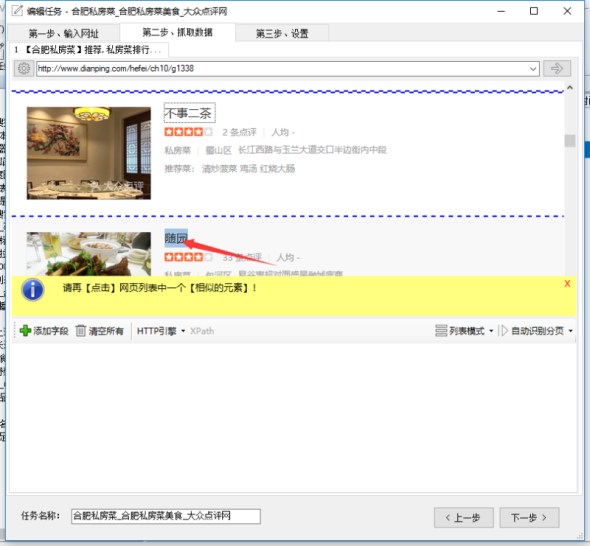
④在点击列表中另一行的一个相似元素。
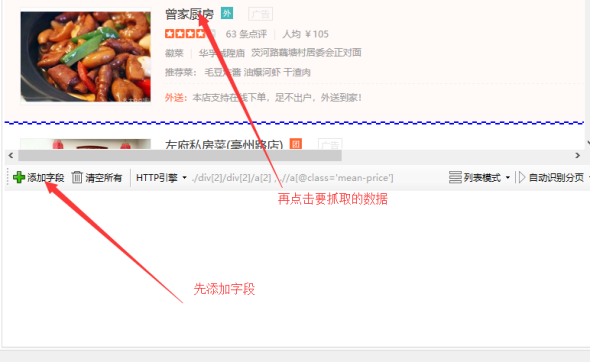
一般情况下,这时采集器会自动列举出列表中的所有字段。我们在对结果进行一些修改即可。
如果没有列举出字段的话,就需要我们手动添加字段。点击【添加字段】,然后点击列表中的元素数据即可。
3、采集文章正文时,鼠标无法选中整个内容时怎么办?
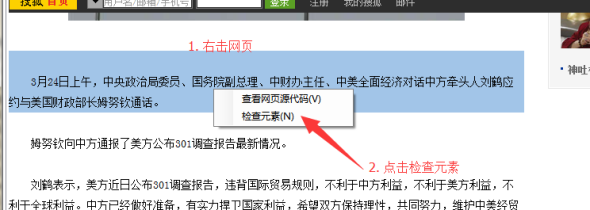
一般情况下,在爬山虎采集器中,通过鼠标点击,选择要抓取的内容。但是在一些情况下,比如要抓取一篇文章的完整内容时,内容较长时,鼠标有时就不好定位了。
①我们可以通过右击网页选择【检查元素】,来定位内容。
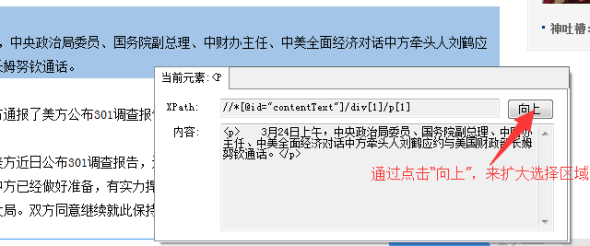
②通过点击【向上】按钮,扩大选择的内容。
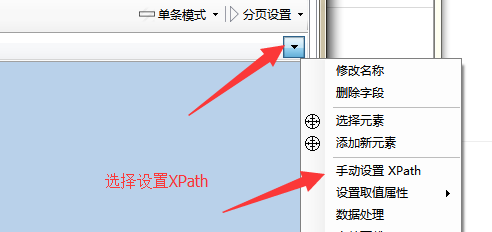
③当扩大到我们的整篇内容时,全选中【XPath】,然后复制。
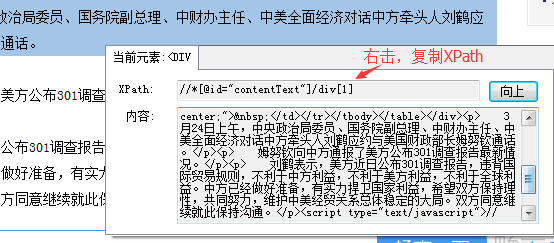
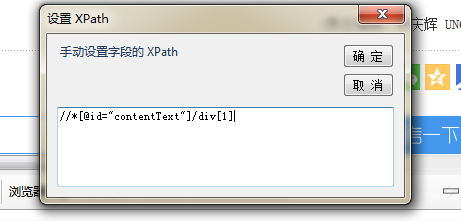
④修改字段的XPath,把刚才复制的XPath粘贴进去,确定。
⑤最后,修改取值属性,想要HMTL就使用InnerHTML或者OuterHTML。
爬山虎采集器
 Postman 官方中文版 v10.20.0.0
Postman 官方中文版 v10.20.0.0
 ADSafe净网大师 官方版 v5.4.521.1800
ADSafe净网大师 官方版 v5.4.521.1800
 Chrome清理工具 电脑版 v93.269.200
Chrome清理工具 电脑版 v93.269.200
 易媒助手 最新版 v2.1.0.7226
易媒助手 最新版 v2.1.0.7226
 Highlight 官方最新版 v4.1
Highlight 官方最新版 v4.1
 智宽生活 官方最新版v4.1.0.5898
智宽生活 官方最新版v4.1.0.5898